
SCD缓慢变化维,比如一个用户维表,用户属性会变化,但是不会变化很剧烈,可能一年只会变化一两次,也不会所有用户的属性都会有变化,只有少量的数据发生变化,所以叫缓慢变化维。这种问题就是由于维度的变化所造成的。
解决方式:
- 是否保留历史数据
- 保留多久历史数据
- 历史状态如何与事实表关联
SCD1 保留最新状态
| 注册日期 | 用户编号 | 手机号码 |
| 2019-01-01 | 0001 | 111111 |
| 2019-01-01 | 0002 | 222222 |
| 2019-01-01 | 0003 | 333333 |
| 2019-01-01 | 0004 | 444444 |
| 注册日期 | 用户编号 | 手机号码 | 备注 |
| 2019-01-01 | 0001 | 111111 | 111111 |
| 2019-01-01 | 0002 | 233333 | (由22222变成23333) |
| 2019-01-01 | 0003 | 333333 | |
| 2019-01-01 | 0004 | 433333 | (由44444变成43333) |
| 2019-01-02 | 0005 | 555555 | (2019-01-02新增) |
缺点:没有任何历史状态,历史发生的事情无法追溯,企业中不关心历史状态的数据,可以使用SCD1
SCD2 保留所有历史状态
| 注册日期 | 用户编号 | 手机号码 |
| 2019-01-01 | 0001 | 111111 |
| 2019-01-01 | 0002 | 222222 |
| 2019-01-01 | 0003 | 333333 |
| 2019-01-01 | 0004 | 444444 |
| 注册日期 | 用户编号 | 手机号码 | t_start_date | t_end_date |
| 2019-01-01 | 0001 | 111111 | 2019-01-01 | 9999-12-31 |
| 2019-01-01 | 0002 | 233333 | 2019-01-01 | 9999-12-31 |
| 2019-01-01 | 0003 | 333333 | 2019-01-01 | 2019-01-01 |
| 2019-01-01 | 0003 | 344444 | 2019-01-02 | 9999-12-31 |
| 2019-01-01 | 0004 | 433333 | 2019-01-01 | 9999-12-31 |
| 2019-01-02 | 0005 | 555555 | 2019-01-01 | 9999-12-31 |
出现问题:同一个用户编号的数据出现多次,与事实表关联时,每个订单就会被关联出多条记录,肯定会出错。
解决办法:加上时间限制条件,订单生成时间在用户表有效期内数据才做关联。
SCD3 只保留了最后一次变化记录,综合了SCD1和SCD2
| 注册日期 | 用户编号 | 手机号码 |
| 2019-01-01 | 0001 | 111111 |
| 2019-01-01 | 0002 | 222222 |
| 2019-01-01 | 0003 | 333333 |
| 2019-01-01 | 0004 | 444444 |
| 注册日期 | 用户编号 | 手机号码 | 先前手机号码 |
| 2019-01-01 | 0001 | 133333 | 111111 |
| 2019-01-01 | 0002 | 233333 | 222222 |
| 2019-01-01 | 0003 | 333333 | |
| 2019-01-01 | 0004 | 444444 |
HIVE实现SCD2
如果关注历史状态基本上用SCD2,如果不关注历史状态就用SCD1,SCD3用得比较少。
SCD2
1,代理键:HIVE中如何实现自增ID
2,如何设计有效期时间
代理键的作用:给下表加一个代理ID,对于一个用户来说,如果状态发生3次变化,在这个表里有3条记录,分别有一个不同的ID。用代理键ID解决有效期问题。
除了在维表中有代理ID,在事实表里也会把用户ID用代理ID替换。关联的时候就不会出现数据重复的问题,就不需要根据有效期无能去做统计了。
| 注册日期 | 用户编号 | 手机号码 | t_start_date | t_end_date |
| 2019-01-01 | 0001 | 111111 | 2019-01-01 | 9999-12-31 |
| 2019-01-01 | 0002 | 233333 | 2019-01-01 | 9999-12-31 |
| 2019-01-01 | 0003 | 333333 | 2019-01-01 | 2019-01-01 |
| 2019-01-01 | 0003 | 344444 | 2019-01-02 | 9999-12-31 |
| 2019-01-01 | 0004 | 433333 | 2019-01-01 | 9999-12-31 |
| 2019-01-02 | 0005 | 555555 | 2019-01-01 | 9999-12-31 |
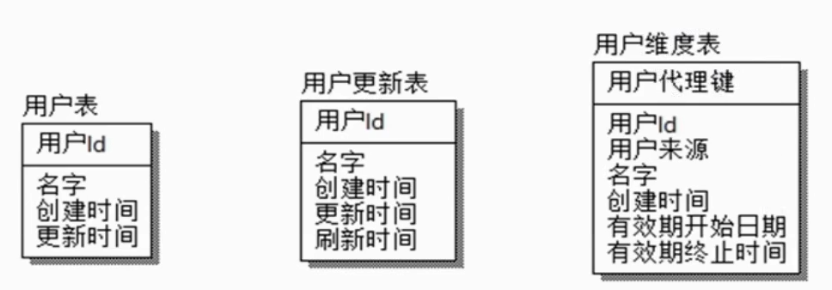
有效期开始时间设计成一个很小的时间,在业务开始之前的时间;
有效期终止时间设计成一个非常大的值,一个固定的值。
Hive中的自增ID
- 利用row_number()
- org.apache.hadoop.hive.contrib.udf.UDFRowSequence
利用row_number()
select row_number() over(order by empno), empno from emp;
利用org.apache.hadoop.hive.contrib.udf.UDFRowSequence
hdfs dfs -mkdir /user/hive/lib
hdfs dfs -put ${HIVE_HOME}/lib/hive-contrib-1.2.1.jar /user/hive/lib/
添加Hive函数
hive>create temporary function row_sequence as 'org.apache.hadoop.hive.contrib.udf.UDFSequence'; hive>select row_sequence(), empno from emp limit 10;
添加Hive永久函数
hive>create function row_sequence as 'org.apache.hadoop.hive.contrib.udf.UDFSequence' using jar 'hdfs:///user/hive/lib/hive-contrib-1.2.1.jar';
准备数据
1,张三,US,CA 2,李四,US,CB 3,王五,CA,BB 4,赵六,CA,BC 5,老刘,AA,AA
创建用户表

-- 可以建成分区表 ,使用文本文件存储格式,因为后面用load加载数据,parquet格式的不支持
drop table if exists ods_user_update;
create table ods_user_update (
user_id INT,
name STRING,
cty STRING,
st STRING
)
COMMENT '每日用户更新表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n'
建立用户维度表
-- 建立维度表 ,数据不能从外部文件加载,只能从一个hive表加载
create database test;
use test;
drop table if exists dim_user;
CREATE TABLE dim_user (
surr_user_id bigint,
user_id INT,
name STRING,
cty STRING,
st STRING,
version INT,
ver_start_date DATE,
ver_end_date DATE)
COMMENT '每日维度表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n'
STORED AS parquet
;
加载初始数据
-- parquet 的表不支持load 数据加载方式 load data local inpath '/root/test/user.txt' overwrite into table ods_user_update;
用户维度表加载初始数据
INSERT INTO dim_user
SELECT
ROW_NUMBER() OVER (ORDER BY ods_user_update.user_id) + t2.sk_max,
ods_user_update.*,
1,
CAST('1900-01-01' AS DATE),
CAST('2200-01-01' AS DATE)
from ods_user_update CROSS JOIN (SELECT COALESCE(MAX(surr_user_id),0) sk_max FROM dim_user) t2;
更新维度表的数据
SET hivevar:pre_date = DATE_ADD(CURRENT_DATE(),-1);
SET hivevar:max_date = CAST('2200-01-01' AS DATE);
load data local inpath '/root/test/user_update.txt' overwrite into table ods_user_update;
INSERT OVERWRITE TABLE dim_user
SELECT * FROM
(
SELECT A.surr_user_id,
A.user_id,A.name,a.cty,a.st,a.version,
A.ver_start_date,
CASE
WHEN B.user_id IS NOT NULL and A.ver_end_date = ${hivevar:max_date} then ${hivevar:pre_date}
ELSE cast(A.ver_end_date as string)
END AS ver_end_date
FROM dim_user AS A LEFT JOIN ods_user_update AS B
ON A.user_id = B.user_id
UNION
select ROW_NUMBER() OVER (ORDER BY C.user_id) + D.sk_max,
c.user_id,c.name,c.cty,C.st,
0,
${hivevar:pre_date} AS ver_start_date,
${hivevar:max_date} AS ver_end_date
from ods_user_update as C cross join (SELECT COALESCE(MAX(surr_user_id),0) sk_max FROM dim_user) D
) AS T
;
