Spark- Linux下安装Spark
前期部署
1.JDK安装,配置PATH
可以参考之前配置hadoop等配置
2.下载spark-1.6.1-bin-hadoop2.6.tgz,并上传到服务器解压
[root@srv01 ~]# tar -xvzf spark-1.6.1-hadoop2.6.tgz /usr/spark-1.6.1-hadoop2.6
3.在 /usr 下创建软链接到目标文件夹
[root@srv01 usr]# ln -s spark-1.6.1-bin-hadoop2.6 spark
4.修改配置文件,目标目录 /usr/spark/conf/
[root@srv01 conf]# ls docker.properties.template log4j.properties.template slaves.template spark-env.sh.template fairscheduler.xml.template metrics.properties.template spark-defaults.conf.template
这里需要把spark-env.sh.template改名为spark-env.sh
export JAVA_HOME=/usr/jdk #这个是单机版的配置,不能实现高可用 export SPARK_MASTER_IP=srv01 export SPARK_MASTER_PORT=7077
再配置slaves ,都是我的集群的机器的hostname
srv01 srv02 srv03
5.分发到集群各个机器上,再软链接一下,保持集群一致性,参考step-3
[root@srv01 usr]# scp -r spark-1.6.1-bin-hadoop2.6 srv02:/usr
[root@srv01 usr]# scp -r spark-1.6.1-bin-hadoop2.6 srv03:/usr
6.Spark-sell
配置好,启动spark-shell,注意记得先关闭防火墙(也可以将spark写进PATH中)
输入 sc ,如果显示下面的,表示安装正常
scala> sc res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@18811c42

7.测试单词计算案例
scala> sc.textFile("/root/file.log").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect.toBuffer
res7: scala.collection.mutable.Buffer[(String, Int)] = ArrayBuffer((scala,2), (spark,2), (hive,1), (hadoop,2), (mapreduce,1), (zookeeper,1), (hello,1), (redis,1), (world,1))
8.启动Spark集群模式(前提是3台机器的spark配置一样,配置文件spark-env.sh和slaves文件保持一致)
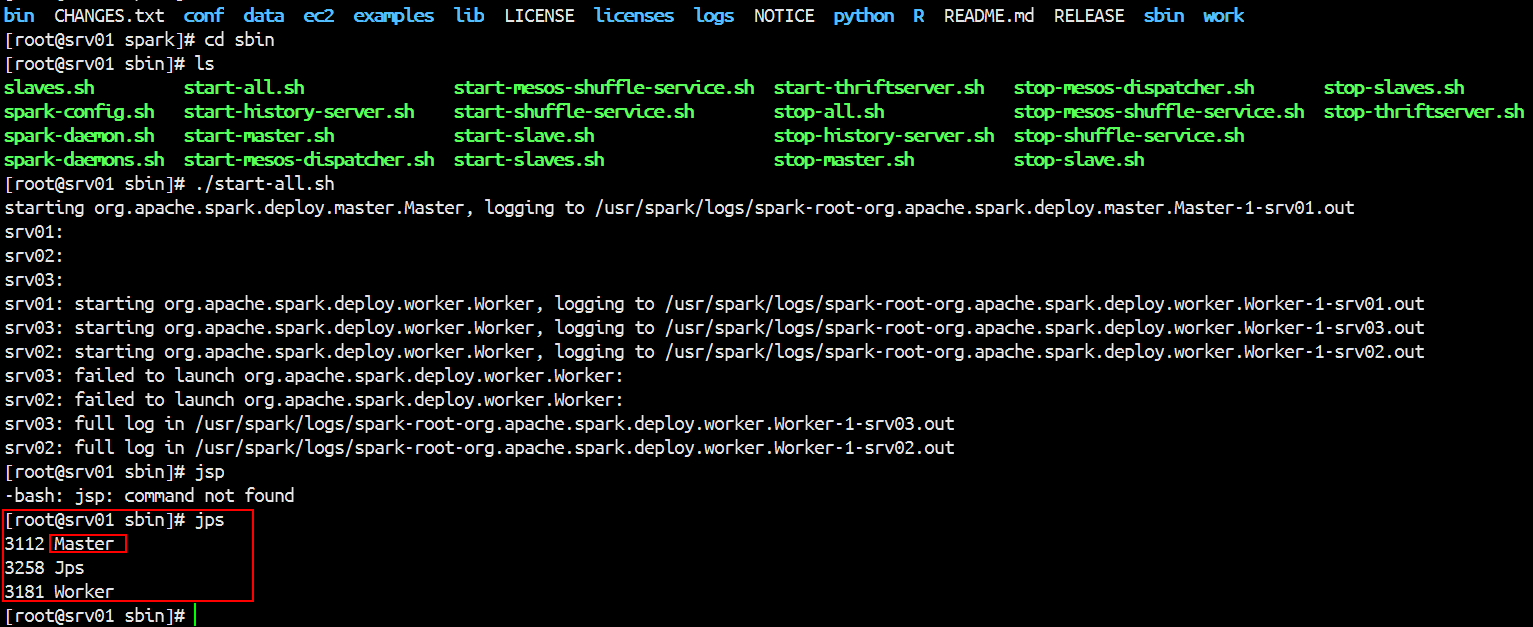
进入Spark的sbin目录下启动 ./start-all.sh
这个脚本文件在sbin目录
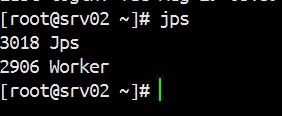
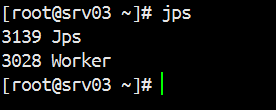
通过Jps查看角色
[root@srv01 conf]# jps
13079 Master
13148 Worker //这个worker的启动通过配置文件slaves
13234 Jps
下面是我的slaves的配置文件
srv01 srv02 srv03
slaves配置的决定了在哪几台机器上启动worker
下面的配置文件决定了在哪台机器上启动Master

启动Spark集群(如果有使用hdfs的场景,需要把hadoop的conf目录下的core-site.xml和dhfs-site.xml拷贝到spark的conf目录下,才能使用高可用的hdfs url)
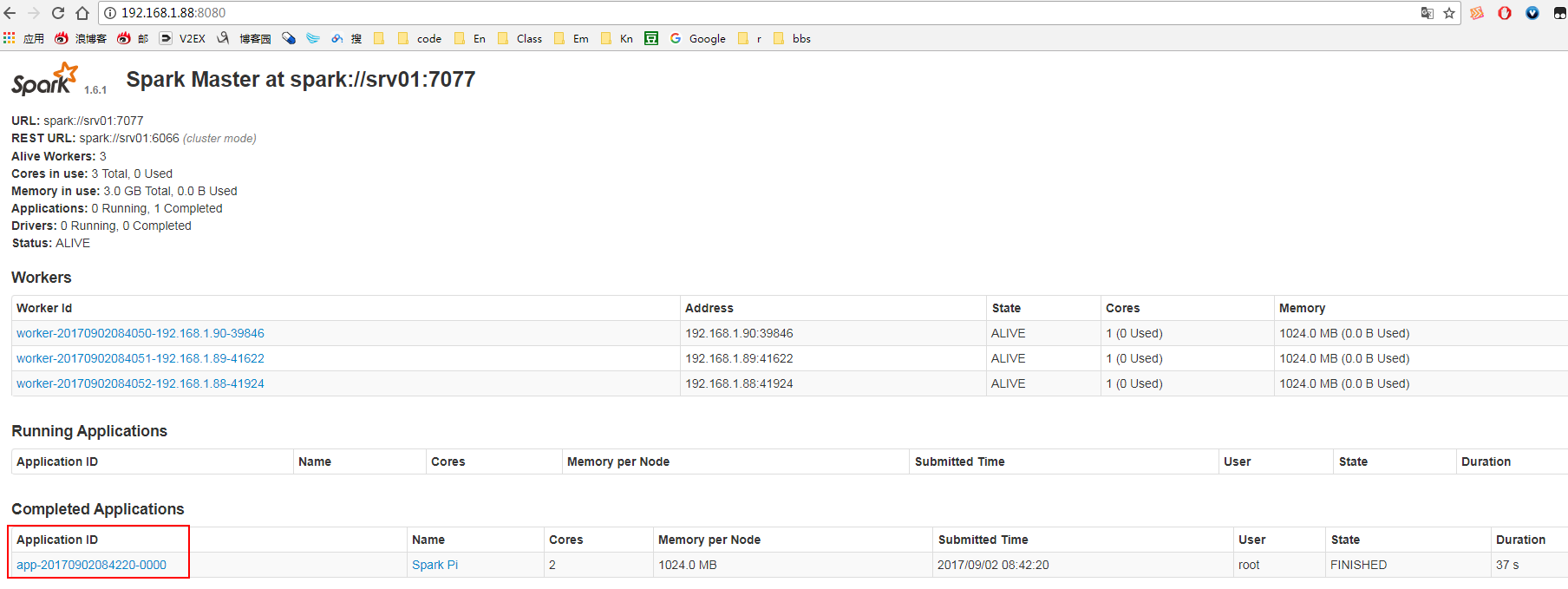
然后在通过网页查看spark的相关信息:
 执行第一个Spark程序
执行第一个Spark程序
 执行第一个Spark程序
执行第一个Spark程序指定运行程序的主机名(Master)
./spark-submit --class org.apache.spark.examples.SparkPi --master spark://srv01:7077 --executor-memory 1G --total-executor-cores 2 /usr/spark-1.6.1-bin-hadoop2.6/lib/spark-examples-1.6.1-hadoop2.6.0.jar 500
IDEA上面编码使用集群上的spark运行程序
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
package com.rz.spark.baseimport org.apache.log4j.{Level, Logger}import org.apache.spark.{SparkConf, SparkContext}object transactionApp { def main(args: Array[String]): Unit = { Logger.getLogger("org.apache.spark").setLevel(Level.OFF) val conf = new SparkConf().setAppName(this.getClass.getSimpleName) .setMaster("spark://hdp:7077") val sc = new SparkContext(conf) val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8,9)) println(rdd1.partitions.length) sc.stop() }} |
