
搭建启动Zookeeper集群出现Error contacting service. It is probably not running解决方案和原理
1.关闭防火墙
|
1
2
3
4
|
[root@srv01 bin]# zkServer.sh startJMX enabled by defaultUsing config: /usr/zookeeper/bin/../conf/zoo.cfgStarting zookeeper ... STARTED |
2.检查zookeeper状态
|
1
2
3
4
|
[root@srv01 bin]# zkServer.sh statusJMX enabled by defaultUsing config: /usr/zookeeper/bin/../conf/zoo.cfgError contacting service. It is probably not running. |
3.查看log日志文件
|
1
|
[root@srv01 bin]# cat zookeeper.out |
以下是相关Exception:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
2017-08-04 14:39:01,523 [myid:1] - INFO [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:FastLeaderElection@849] - Notification time out: 600002017-08-04 14:40:01,525 [myid:1] - WARN [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:QuorumCnxManager@382] - Cannot open channel to 2 at election address srv02/192.168.1.89:3888java.net.ConnectException: 拒绝连接 (Connection refused) at java.net.PlainSocketImpl.socketConnect(Native Method) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:589) at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:368) at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectAll(QuorumCnxManager.java:402) at org.apache.zookeeper.server.quorum.FastLeaderElection.lookForLeader(FastLeaderElection.java:840) at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:762)2017-08-04 14:40:01,528 [myid:1] - WARN [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:QuorumCnxManager@382] - Cannot open channel to 3 at election address srv03/192.168.1.90:3888java.net.ConnectException: 拒绝连接 (Connection refused) at java.net.PlainSocketImpl.socketConnect(Native Method) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:589) at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:368) at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectAll(QuorumCnxManager.java:402) at org.apache.zookeeper.server.quorum.FastLeaderElection.lookForLeader(FastLeaderElection.java:840) at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:762)2017-08-04 14:40:01,529 [myid:1] - INFO [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:FastLeaderElection@849] - Notification time out: 600002017-08-04 14:40:43,444 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@197] - Accepted socket connection from /127.0.0.1:582172017-08-04 14:40:43,444 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing srvr command from /127.0.0.1:582172017-08-04 14:40:43,445 [myid:1] - INFO [Thread-3:NIOServerCnxn@1007] - Closed socket connection for client /127.0.0.1:58217 (no session established for client) |
注意颜色字体,意思是无法打开选举通道2和3,造成的原因是,zookeeper集群开启时有个选举过程,此时我仅开启一台机器,由于其他两台机器没有开启,它发出去的报文没有任何响应,导致它的选举状态一直处于LOOKING状态。
同时把另外两台机器srv02,srv03开启,3台机器组网形成集群,立即选举出leader就能清晰地看到zookeeper集群的状态了。
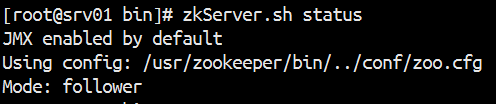
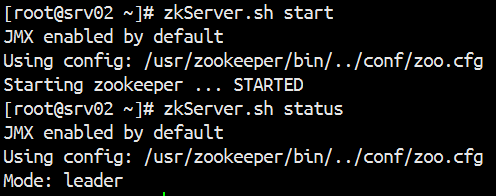
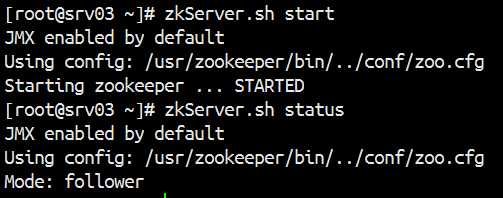
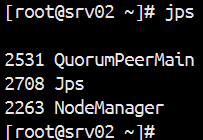
用命令 jps 查看进程是否开启
要清晰的处理这个问题就要从zookeeper的选举机制来了解
简单的例子来说明整个选举的过程.

zookeeper的选举机制(全新集群paxos) 以一个简单的例子来说明整个选举的过程. 假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的.假设这些服务器依序启动,来看看会发生什么. 1) 服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态 2) 服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1,2还是继续保持LOOKING状态. 3) 服务器3启动,根据前面的理论分析,服务器3成为服务器1,2,3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader. 4) 服务器4启动,根据前面的分析,理论上服务器4应该是服务器1,2,3,4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了. 5) 服务器5启动,同4一样,当小弟. 非全新集群的选举机制(数据恢复) 那么,初始化的时候,是按照上述的说明进行选举的,但是当zookeeper运行了一段时间之后,有机器down掉,重新选举时,选举过程就相对复杂了。 需要加入数据id、leader id和逻辑时钟。 数据id:数据新的id就大,数据每次更新都会更新id。 Leader id:就是我们配置的myid中的值,每个机器一个。 逻辑时钟:这个值从0开始递增,每次选举对应一个值,也就是说: 如果在同一次选举中,那么这个值应该是一致的 ; 逻辑时钟值越大,说明这一次选举leader的进程更新. 选举的标准就变成: 1、逻辑时钟小的选举结果被忽略,重新投票 2、统一逻辑时钟后,数据id大的胜出 3、数据id相同的情况下,leader id大的胜出 根据这个规则选出leader。
